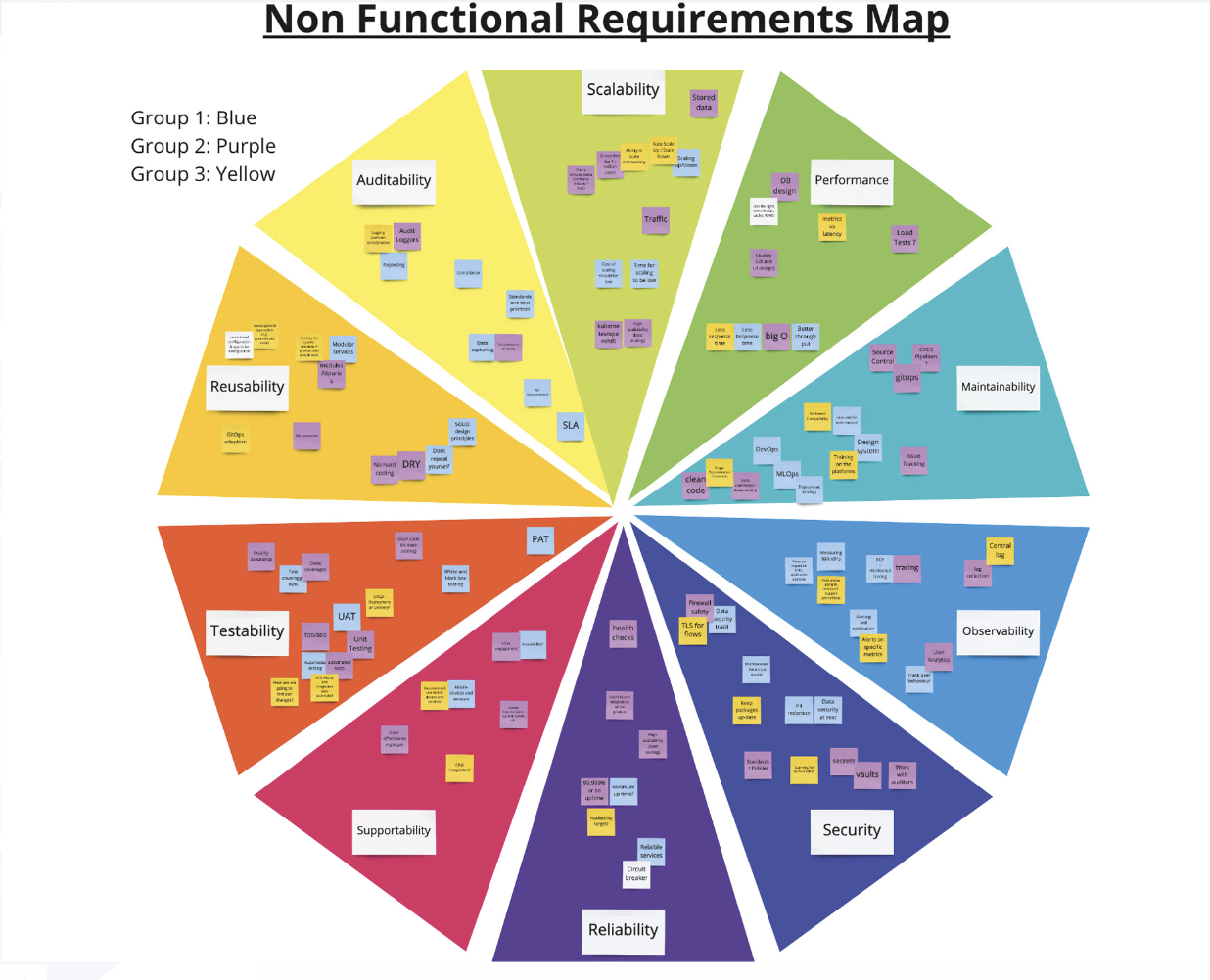
NFRs
Categories:
Introduction
When you work on a DevOps or SRE team, you’re likely to have lists of NFRs to base performance against, or to aide in system designs.
This is especially true as a consultant. Coming into customer environments with little insight into the business, the workloads, or the day-to-day experience makes the architecture of their future solutions a blind effort at best. Therefore, well-defined NFRs are vital to driving a successful transformation and maintaining optimal performance long-term.
What are Non-Functional Requirements (NFRs)?
Non-Functional Requirements (NFRs) are the critical performance characteristics of a software system that ensure it meets the needs of its users and the business. In the context of container orchestration platforms like OpenShift and Kubernetes, NFRs are especially important as they determine the system’s ability to handle workloads, ensure high availability, provide secure access controls, and deliver optimal performance.
If you aren’t already familiar, OpenShift is a container application platform that builds on top of Kubernetes to provide additional features and capabilities for deploying and managing applications. Kubernetes is a widely adopted open-source container orchestration platform that provides a scalable and flexible infrastructure for containerized applications.
While Kubernetes provides a strong foundation for deploying and managing containerized applications, OpenShift adds features such as automated deployment, built-in monitoring and logging, and integrated security to enhance the platform’s capabilities.
To ensure that OpenShift and Kubernetes meet the needs of organizations, it’s essential to consider NFRs when deploying and managing containerized applications. NFRs such as scalability, availability, security, performance, reliability, compliance, manageability, interoperability, disaster recovery, cost effectiveness, observability, durability, agility, and extensibility, provide a framework for evaluating the platform’s capabilities and effectiveness in meeting the needs of the organization.
In this post, we will explore many of these NFRs in the context of OpenShift and Kubernetes, explaining their significance and how they can be measured and evaluated. We will also discuss the functions and integrations within OpenShift that support each NFR and provide guidance on how to optimize these capabilities for a successful containerized application deployment. By considering these NFRs, organizations can ensure that their containerized applications are scalable, secure, reliable, and optimized for performance and cost-effectiveness.
OpenShift/K8s Platform NFRs
There are many potential NFRs for a platform. The following are a subset of some of the core NFRs encountered in the context of OpenShift.
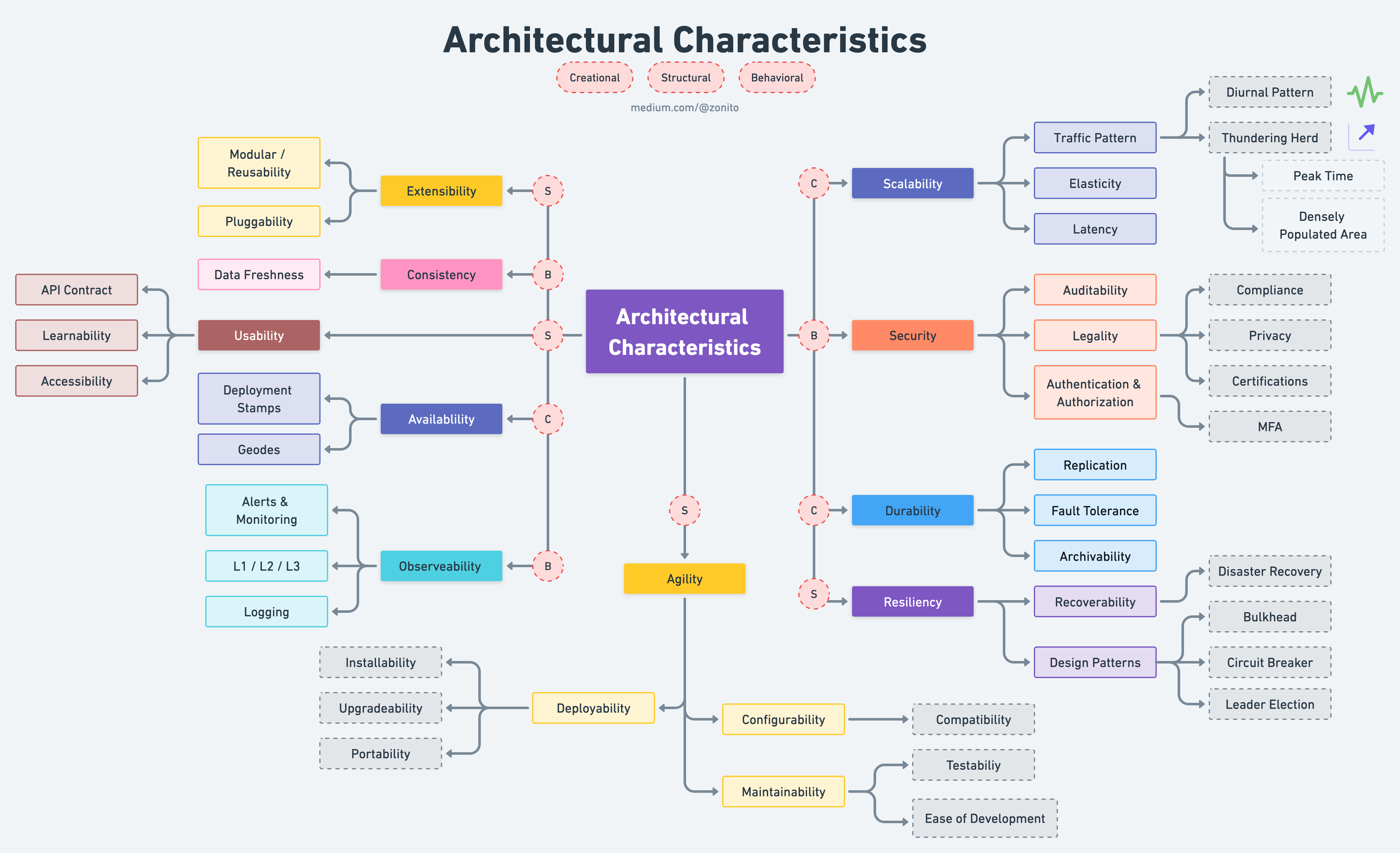
Scalability
OpenShift provides a scalable container platform that can handle an increasing number of users, applications, and workloads.
OpenShift enables horizontal scaling of applications with Kubernetes, allowing developers to scale up or down the number of replicas of an application depending on demand.
Metrics such as CPU utilization, memory usage, and network I/O can be monitored to measure the platform’s scalability.
Traffic Pattern
Understand the system’s traffic pattern. Three sample patterns:
- Diurnal - Traffic increases in the morning and decreases in the evening for a particular region.
- Global/regional - Heavy usage of the application in a particular region.
- Thundering herd - Many users request resources, but only a few machines are available to serve the burst of traffic. This could occur during peak times or in densely populated areas.
Elasticity
This relates to the ability to quickly spawn a few machines to handle the burst of traffic and gracefully shrink when the demand is reduced.
Latency
This is the system’s ability to serve a request as quickly as possible. This also includes optimizing the algorithms and using edge computing to replicate the system near users to reduce the round-trip time of a request.
Availability
OpenShift provides high availability with a minimum downtime for maintenance, upgrades, and failures.
OpenShift leverages Kubernetes to provide automated failover and recovery of workloads, ensuring that applications remain available even in the event of a node failure.
Metrics such as mean time to recover (MTTR) and mean time between failures (MTBF) can be used to measure availability.
Deployment Stamps
Deploy multiple independent copies of application components, including data stores.
Geodes
Deploy backend services into a set of geographical nodes, each of which can service any client request in any region.
Security
OpenShift provides secure access controls, data encryption, and network segmentation to ensure data protection.
OpenShift integrates with Kubernetes to provide container-level security features such as RBAC (Role-Based Access Control), pod security policies, and network policies. OpenShift also supports integration with third-party security tools such as Twistlock and Aqua Security to provide advanced threat detection and prevention capabilities.
Metrics such as number of security incidents and response time to security incidents can be used to measure security.
Confidentiality
Data is accessible only to those authorized to have access.
Integrity
The software prevents unauthorized access to or modification of software or information.
Nonrepudiation
Prove whether actions or events have taken place.
Accountability
Trace user actions.
Authenticity
Prove the user’s identity.
Other Security Areas
- Auditability - Audit trails track system activity so that when a security breach occurs, you can determine the mechanism and extent of the breach. Storing audit trails remotely, where they can only be appended, can keep intruders from covering their tracks.
- Legality - This involves adherence to laws or other industry requirements.
- Compliance - Adherence to data protection laws like GDPR, CCPA, SOC2, PIPL, or FedRamp. OpenShift supports integration with third-party compliance tools such as Sysdig Secure and Red Hat Insights.
- Privacy - Ability to hide transactions from internal company employees, such as encrypting transactions so that even database administrators and network architects cannot see them
- Authentication - Security requirements ensure users are who they say they are.
- Authorization - Security requirements ensure users can access only certain functions within the application (by use case, subsystem, web page, business rule, field level, and so forth).
Performance
OpenShift delivers high performance with low latency, high throughput, and efficient resource utilization.
OpenShift integrates with Kubernetes to provide features such as autoscaling, load balancing, and resource utilization monitoring to optimize performance.
Metrics such as response time, throughput, and resource utilization can be used to measure performance.
Durability
OpenShift must be highly durable and provide reliable performance under heavy workloads and in the event of hardware or software failures.
OpenShift provides features such as self-healing, automatic scaling, and load balancing to help ensure durability and performance. OpenShift also supports high availability through the use of multiple replicas and redundant storage. OpenShift integrates with storage solutions such as GlusterFS and Ceph for highly durable storage.
Metrics such as availability, uptime, and error rates can be used to measure durability effectiveness.
Replication
Share information to ensure consistency between redundant resources to improve reliability, fault-tolerance, or accessibility.
Fault Tolerance
This enables a system to continue operating correctly in the event of one or more faults within some of its components.
Archivability
This manages whether the data needs to be archived or deleted after a period of time.
Agility
OpenShift must provide agility to rapidly deploy and scale applications, with the ability to quickly adapt to changing business needs.
OpenShift provides features such as automated application deployment and scaling, with support for a variety of deployment models including container images, Helm charts, and serverless functions. OpenShift also supports agile development methodologies such as DevOps, with built-in continuous integration and delivery (CI/CD) pipelines. OpenShift integrates with tools such as Jenkins, GitLab, and GitHub for further agility and automation.
Metrics such as lead time and cycle time can be used to measure agility effectiveness.
Maintainability
How easy is it to apply changes and enhance the system?
- Testability
- Ease of Development
Deployability
This is the time it takes to get code into production.
- Installability
- Upgradeability
- Portability
Configurability
How easily can end users change aspects of the software’s configuration (through usable interfaces)?
Compatibility
How well can a product, system, or component exchange information with other products, designs, or members and perform its required functions while sharing the same hardware or software environment?
Extensibility
OpenShift provides a web-based console, command-line interface (CLI), and API for managing the platform. OpenShift also integrates with monitoring and logging tools such as Prometheus, Grafana, and Elasticsearch to provide real-time visibility into platform performance and health.
OpenShift must be extensible, easy to manage, and allow for integration with third-party tools and services, as well as customizations and extensions to meet specific business needs.
OpenShift provides an open and extensible platform, with support for a variety of programming languages and frameworks. OpenShift also provides a web-based console, command-line interface (CLI), and API for managing the platform.OpenShift integrates with a variety of third-party tools and services such as databases, message brokers, and machine learning frameworks. OpenShift also allows for customizations and extensions through the use of operators and APIs.
Metrics such as time to market for new features and integrations, and time to deploy applications, can be used to measure extensibility effectiveness.
Modularity and Reusability
Reusability, together with extensibility, allows technology to be transferred to another project with less development and maintenance time, as well as enhanced reliability and consistency.
Pluggability
This is the ability to easily plug in other components, for example with microkernel architecture.
Resiliency
OpenShift must have a disaster recovery plan and backup strategy in place to ensure business continuity in the event of a disaster.
OpenShift provides features such as backup and restore, disaster recovery replication, and application replication to enable business continuity. OpenShift enables backup and restore of the entire cluster or specific applications, including persistent storage. OpenShift also supports disaster recovery replication between clusters, which allows for seamless failover in the event of a disaster. Additionally, OpenShift enables application replication across multiple clusters or cloud providers, which helps to minimize downtime and ensure business continuity.
Metrics such as recovery point objective (RPO) and recovery time objective (RTO) can be used to measure resiliency effectiveness.
Disaster Recovery
Consists of best practices designed to prevent or minimize data loss and business disruption resulting from catastrophic events—everything from equipment failures and localized power outages to cyber-attacks, civil emergencies, criminal or military attacks, and natural disasters.
Bulkhead
This pattern isolates elements of an application into pools so that if one fails, the others will continue to function.
Circuit Breaker
This pattern handles faults that might take a variable amount of time to fix when connecting to a remote service or resource.
Leader Election
This pattern coordinates the actions performed by a collection of collaborating task instances in a distributed application by electing one instance as the leader that assumes responsibility for managing the other instances.
Cost Effectiveness
OpenShift must be cost-effective, with minimal infrastructure and maintenance costs, and support pay-as-you-go pricing models.
OpenShift provides a variety of deployment options, including on-premises, public cloud, and hybrid cloud, allowing organizations to choose the deployment model that is most cost-effective for their needs. OpenShift provides a number of features that help reduce infrastructure and maintenance costs, including automated management, self-healing, and integrated monitoring and logging. OpenShift also supports a variety of pricing models, including pay-as-you-go and subscription-based pricing, to help organizations optimize costs.
Metrics such as cost per user, cost per application, and total cost of ownership (TCO) can be used to measure cost effectiveness. Additionally, OpenShift integrates with a number of third-party cost optimization tools, such as Cloudability and Turbonomic, to help organizations optimize their cloud spending and reduce costs.
Observability
OpenShift must provide observability into the platform and its applications, with metrics, logs, and traces readily available to support monitoring and troubleshooting.
OpenShift provides built-in monitoring and logging capabilities, with integrated Prometheus and Grafana for metrics, and Fluentd and Elasticsearch for logs. OpenShift also integrates with other observability tools such as Jaeger and Zipkin for distributed tracing. OpenShift supports the collection, storage, and analysis of data from across the platform, including Kubernetes and applications running on the platform.
Metrics such as mean time to detect (MTTD) and mean time to resolve (MTTR) can be used to measure observability effectiveness.
Logging
There are different types of logs generated within each request, such as event logs, transaction logs, message logs, and server logs.
Alerts & Monitoring
Prepare monitoring dashboards, create service-level indicators (SLIs), and set up critical alerts.
Tiered Levels of Support
L1 support includes interacting with customers. L2 support manages the tickets escalated by L1 and helps troubleshoot. L3 is the last line of support and usually comprises a development team that addresses the technical issues.
References
- The two scales of DevOps
- Nonfunctional requirements: A checklist - IBM Cloud Architecture Center
- The Non-Functional Map | DevOps Culture and Practice with OpenShift
- 10 nonfunctional requirements to consider in your enterprise architecture
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.